动画渲染
兼容90%CG软件,渲染提速400倍
就在大家被虚幻引擎5的渲染技术Nanite和动态全局光照技术Lumen震惊得还没回过神儿的时候,NVIDIA创始人兼CEO黄仁勋在自家厨房开始了GTC 2020主题演讲,端出了“新鲜出炉”的“核弹基地”——NVIDIA A100,全球最大的GPU,具备全新安培(Ampere)架构,7nm工艺,540亿晶体管,20倍AI算力提升。




©英伟达官方
基于Ampere(安培)架构的GPU——NVIDIA A100
首款基于Ampere架构的GPU —— NVIDIA A100,目前已全面投产并已向全球客户交付。NVIDIA Ampere 架构实现了革命性的数据分析、训练和推理性能。
A100采用了NVIDIA Ampere架构的突破性设计,该设计为NVIDIA第八代GPU提供了迄今为止最大的性能飞跃,首个弹性、多实例GPU,集数据分析、AI训练和推理于一身,并且其性能相比于前代产品提升了高达20倍。作为一款通用型工作负载加速器,A100还被设计用于数据分析、科学计算和云图形,被全球顶级云供应商和服务器制造商所采用。

©英伟达官方
NVIDIA创始人兼首席执行官黄仁勋表示:“云计算和AI的强大趋势正在推动数据中心设计的结构性转变,过去的纯CPU服务器正在被高效的加速计算基础架构所取代。NVIDIA A100 GPU作为一个端到端的机器学习加速器,其实现了从数据分析到训练再到推理20倍的AI性能飞跃。这是有史以来首次,可以在一个平台上实现对横向扩展以及纵向扩展的负载的加速。NVIDIA A100将在提高吞吐量的同时,降低数据中心的成本。”
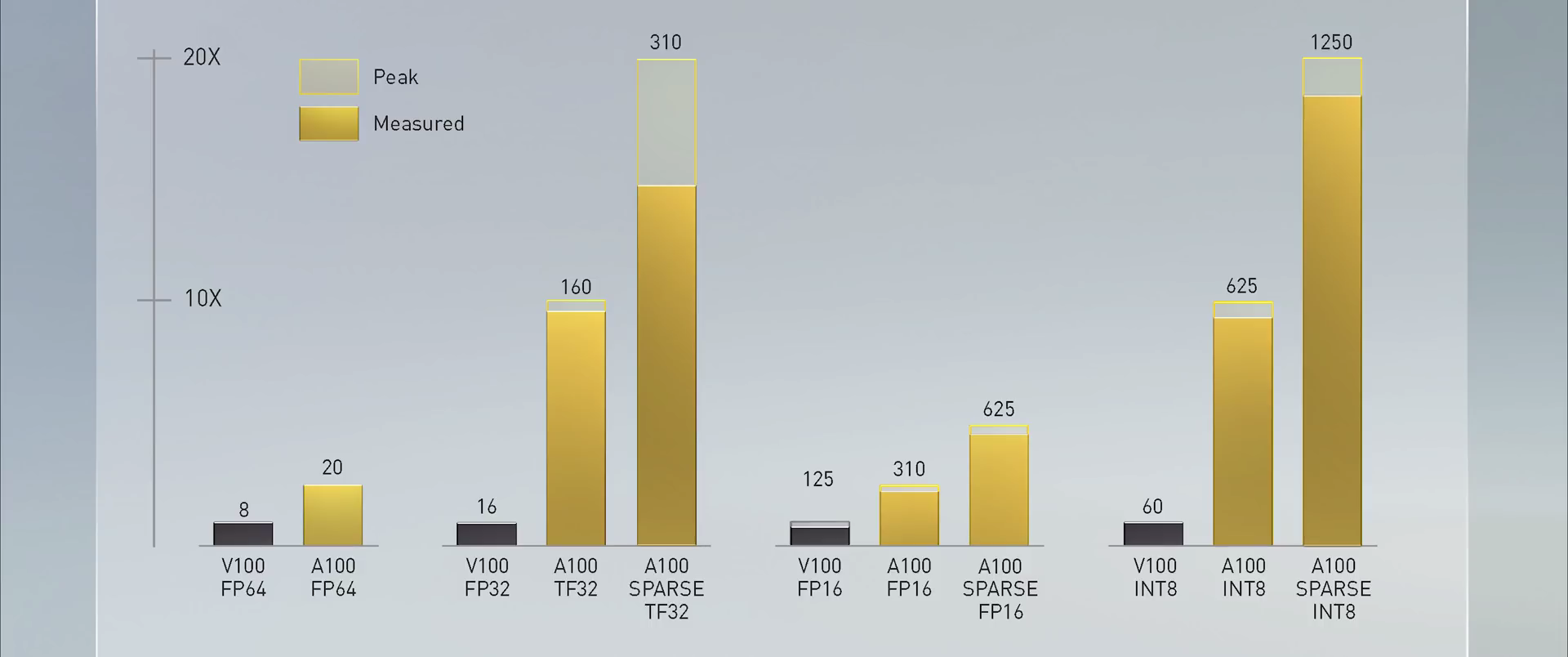
©英伟达官方
A100所采用的全新弹性计算技术能够为每项工作分配适量的计算能力。多实例GPU技术可将每个A100GPU分割为多达七个独立实例来执行推理任务,而第三代NVIDIA NVLink互联技术能够将多个A100GPU合并成一个巨大的GPU来执行更大规模的训练任务。
A100的五大突破
NVIDIAA100 GPU的突破性技术设计来源于五大关键性创新:
A100的核心是NVIDIA Ampere GPU架构:
该架构包含超过540亿个晶体管,这使其成为全球最大的7纳米处理器。
具有TF32的第三代Tensor Core核心:
NVIDIA广泛采用的Tensor Core核心现在已变得更加灵活、快速且易于使用。其功能经过扩展后加入了专为AI开发的全新TF32,它能在无需更改任何代码的情况下,使FP32精度下的AI性能提高多达20倍。此外,Tensor Core核心现在支持FP64精度,相比于前代,其为HPC应用所提供的计算力比之前提高了多达2.5倍。
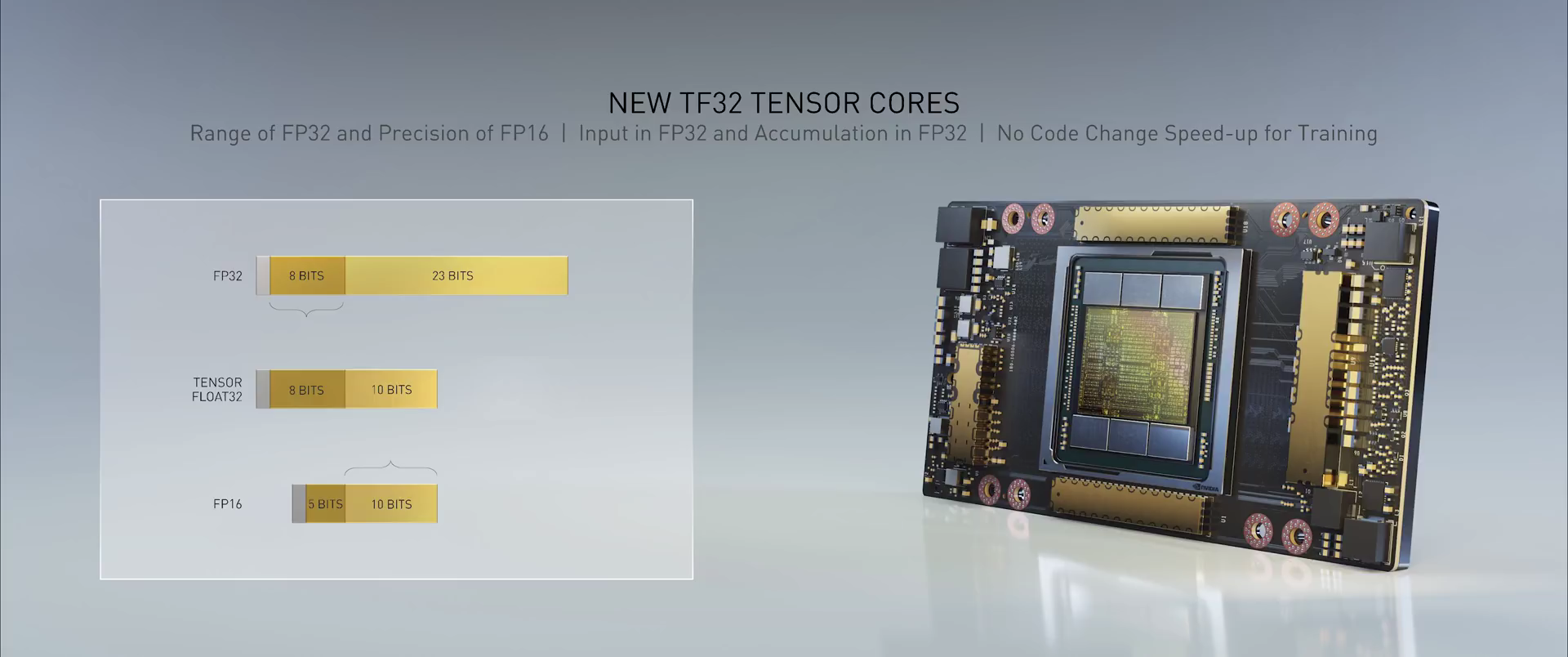
©英伟达官方
多实例GPU:
MIG,一种全新技术功能,可将单个A100 GPU分割为多达七个独立的GPU,为不同规模的工作提供不同的计算力,以此实现最佳利用率和投资回报率的最大化。
第三代NVIDIA NVLink:
使GPU之间的高速联接增加至原来的两倍,实现服务器的高效性能扩展。
结构化稀疏:
这种全新效率技术利用AI数学固有的稀疏性,使性能提升了一倍。
凭借这些新功能,NVIDIA A100成为了AI训练和推理以及科学模拟、对话式AI、推荐系统、基因组学、高性能数据分析、地震建模和金融预测等各种高要求工作负载的理想选择。
这些特性促成了A100性能的提升:与NVIDIA上一代的Volta架构相比,训练性能提高了6倍,推理性能提高了7倍。
新系统已搭载NVIDIA A100,很快将登陆云端
新发布的还有NVIDIA DGX™ A100 系统,其内置8个由NVIDIA NVLink互联的NVIDIA A100 GPU。


DGX A100系统分解图 © 英伟达官方
NVIDIA还宣布了下一代DGX SuperPOD。它由140台DGX A100系统和Mellanox网络技术搭建而成,可提供700 petaflops的AI性能,堪比全球20台最快的计算机中的任何一台。

新一代DGX SuperPOD实现了强达每秒70 petaflops的AI算力©英伟达官方
为帮助合作伙伴加快服务器的开发,NVIDIA开发了HGX A100服务器构建模块,该模块采用了多GPU配置的集成基板形式。

©英伟达官方
HGX A100 4-GPU通过NVLink实现GPU之间的完整互联,8-GPU配置的HGX A100通过NVIDIA NVSwitch实现GPU之间的全带宽通信。采用全新MIG技术的HGXA100能够被分割为56个小型GPU,每个GPU的速度都比NVIDIA T4更快;或者也可以将其用作一台拥有10petaflopsAI性能的巨型8-GPU服务器。
A100软件优化
NVIDIA还发布了多个软件堆栈更新,使应用程序开发者能够充分发挥A100 GPU创新技术的性能。这些更新包括了50多个新版本CUDA-X™ 库,可用于加速图形、模拟和AI;CUDA11;多模态对话式AI服务框架NVIDIA Jarvis;深度推荐应用框架 NVIDIA Merlin;以及NVIDIA HPC SDK,其中包括能够帮助HPC开发者调试和优化A100代码的编译器、库和工具。
在全球范围内被迅速采用
Microsoft(微软)是首批采用NVIDIAA100 GPU的用户之一,计划充分利用其性能和可扩展性。
Microsoft公司副总裁MikhailParakhin表示:
“Microsoft大规模应用前代NVIDIA GPU训练了全球最大的语言模型——TuringNatural Language Generation。Azure将使用NVIDIA 新一代A100 GPU训练更大型的AI模型,以推动语言、语音、视觉和多模态技术领域的最新发展。”
DoorDash是一个按需提供的食品平台,在大流行期间作为餐馆的生命线,它指出了拥有灵活的人工智能基础设施的重要性。
DoorDash的机器学习工程师Gary Ren表示:
“现代复杂AI训练和推理工作负载需要处理大量的数据,像NVIDIA A100 GPU这样最先进的技术,可以帮助缩短模型训练时间,加快机器学习开发进程。此外,采用基于云的GPU集群还能够为我们提供更高的灵活性,可以根据需要扩容或缩容,将有助于提高效率、简化操作并节约成本。”
NVIDIA RTX 服务器
两年NVIDIA前在SIGGRAPH 2018发布了RTX,开启了计算机图形的新纪元。

©英伟达官方
NVIDIA RTX 服务器采用高度灵活的服务器参考设计,结合了 NVIDIA Quadro RTX™ 6000和8000 GPU 与 NVIDIA 虚拟 GPU (vGPU)软件和行业领先的第三方应用程序,以提供卓越的计算能力。
RTX服务器提供了一系列经过验证的解决方案,从虚拟工作站和渲染到可扩展视觉系统和边缘计算,借助NVIDIA RTX服务器,用户能以远低于传统CPU解决方案的成本、空间和功耗,获得前所未有的性能。

NVIDIA RTX Server © 英伟达官方
NVIDIA RTX 服务器适用场景包括:虚拟工作站、渲染、计算机辅助工程(CAE)、协同设计、AR/VR、可扩展可视化解决方案。

NVIDIA RTX 服务器应用场景 © 英伟达官方
RTX赋力Omniverse View:新型渲染器兼顾实时速度与离线质量
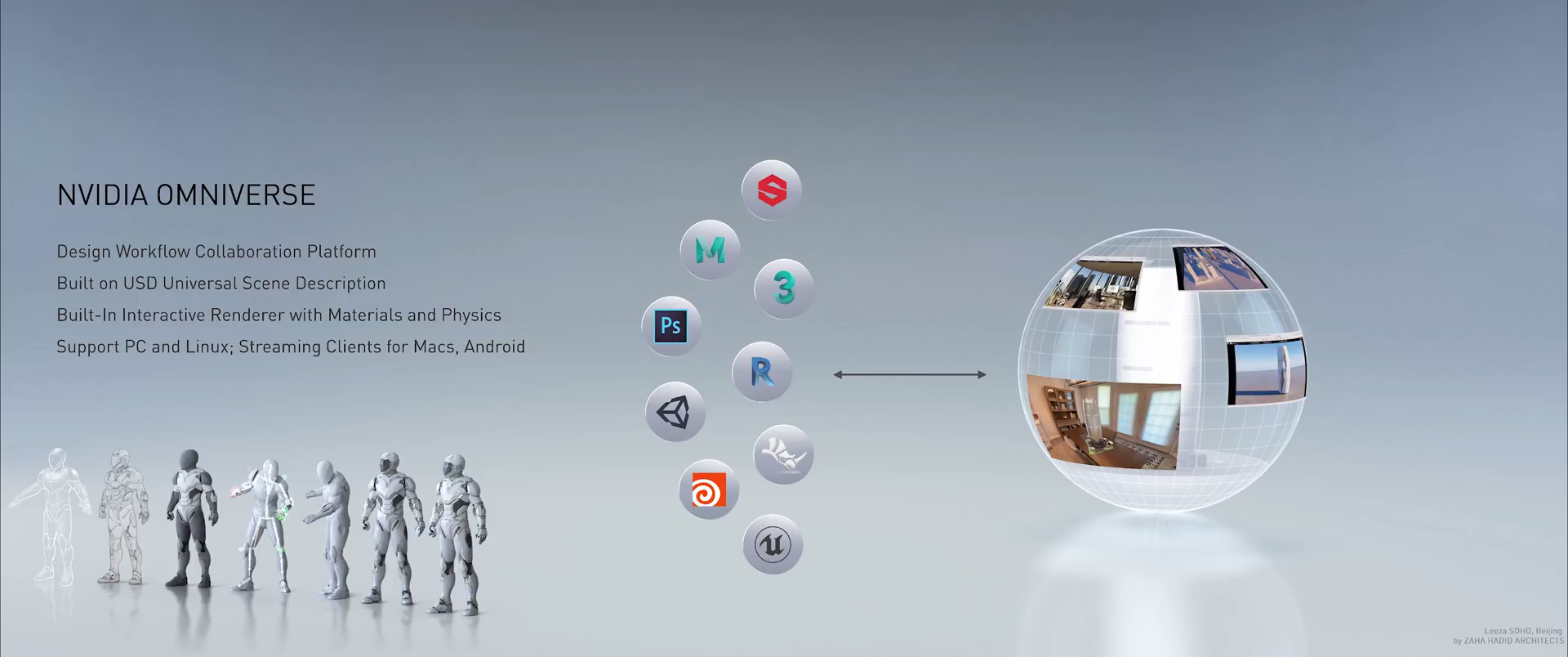
NVIDIA Omniverse是一个计算机图形和仿真模拟平台,能够让艺术家实现实时无缝协作,无论是跨本地部署的软件应用还是通过云端的全球协作。该平台现已向建筑、工程和施工(AEC)市场的早期体验客户开放。
Omniverse View可集中显示Omniverse内部不同应用中的3D内容,或者直接显示使用中的3D应用中的内容。它还支持商业游戏引擎,如Unreal Engine和Unity,以及离线渲染器。
目前,市面上有两种类型的渲染器。实时渲染一般在以每秒30或60帧的速度生成图像,并始终根据目标用途使用最低配置的设备。离线渲染侧重于提供逼真的最终图像或场景,每帧都需要使用CPU花费数小时进行渲染。为了达到最佳速度,许多角落通常会被截掉(从简化几何图形到烘焙照明和法线贴图),这也导致了图像质量的降低。
© 英伟达官方
为了解决这个问题,Omniverse通过Omniverse View引入了一种新型渲染。该模块由多个NVIDIA RTX GPU加速并且可以在GPU阵列上实现极高的可扩展性,即便是在超大型场景中也能提供高质量的实时输出。
黄仁勋还展示了“Marbles”这一具有动态照明实时物理特性和丰富物理材质的娱乐游戏环境,以及该平台最新的“AEC Experience”功能集。该功能集通过实时可视化实现CAD应用之间的无缝连接。
NVIDIA DLSS 2.0
DLSS 2.0 由 GeForce RTX GPU 上的专用 AI 处理器(称为 Tensor Core)提供支持,是一个经过改进的全新深度学习神经网络,能够提高帧速率,同时生成精美、清晰的游戏图像。DLSS 2.0 为玩家提供了充足的性能,有助于最大化光线追踪设置,并提高输出分辨率。
在主题演讲中,NVIDIA为《我的世界》RTX版发布5个全新地图,通过RTX技术为这款全球最畅销的游戏之一提供了令人惊叹的画面质量,在这个新地图中玩家们可以尽情探索美丽的世界。


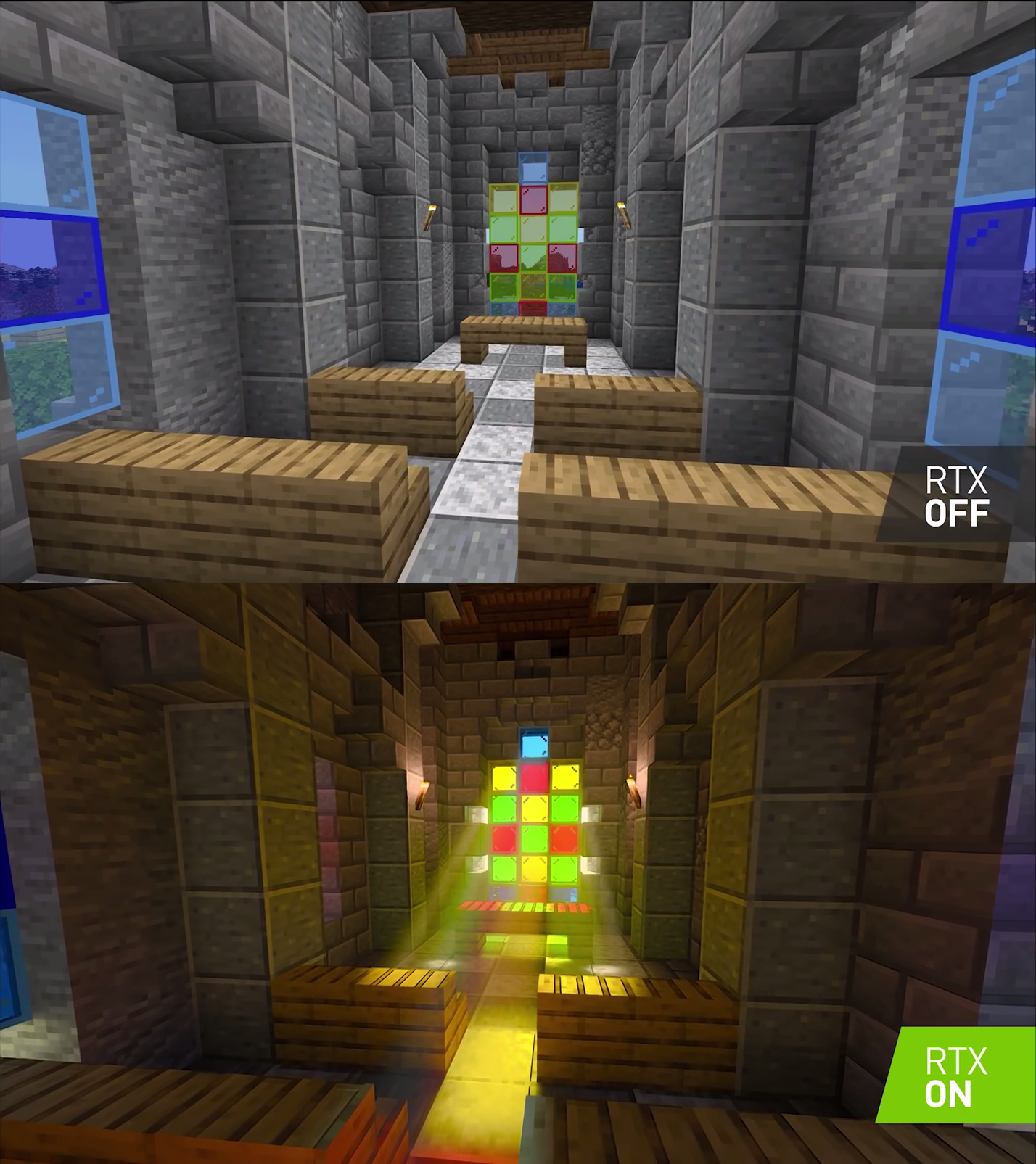

素材源自英伟达官方
NVIDIA RTX GPU x 3DCAT实时渲染云
瑞云科技旗下3DCAT实时渲染云是一个三维应用的托管运行平台,在云端部署了NVIDIA RTX GPU,提供强大的图形实时渲染计算服务,支持能在Windows平台渲染的包括虚幻引擎在内的几乎所有引擎,支持自动负载均衡和伸缩扩容,支持海量用户同时安全访问应用。

黄教主的厨房演讲还包括很多重磅黑科技,包括:NVIDIA CloudXR、NVIDIA HPC SDK、CUDA 11等,感兴趣的小伙伴可以去NVIDIA官网深入了解,或者在公众号后台回复“GTC2020”即可获取《NVIDIA GTC 2020 Keynote》演讲视频及字幕。

©英伟达官方
瑞云科技专注于为视觉行业提供垂直云计算SaaS服务,同时作为英伟达深度合作伙伴,聚焦行业领域先进技术,将不断优化提升,带来更优质的服务与体验 ,竭诚为各位用户提供高效优质的技术与服务。
素材源自NVIDIA

2026-05-19

2026-05-13

2026-05-12

2026-04-29

2026-04-21

2026-04-07









