动画渲染
兼容90%CG软件,渲染提速400倍










关于渲染农场的十大常见问题
2021-10-20

新手指南:易上手的高铁站渲染软件推荐
2025-09-29

3ds Max云渲染:瑞云渲染农场赋能高效创作,解锁专业级渲染新体验
2025-09-22

从新手到大师都在冲!这场世界规模最大3d渲染挑战赛,你知道吗?
2025-08-25
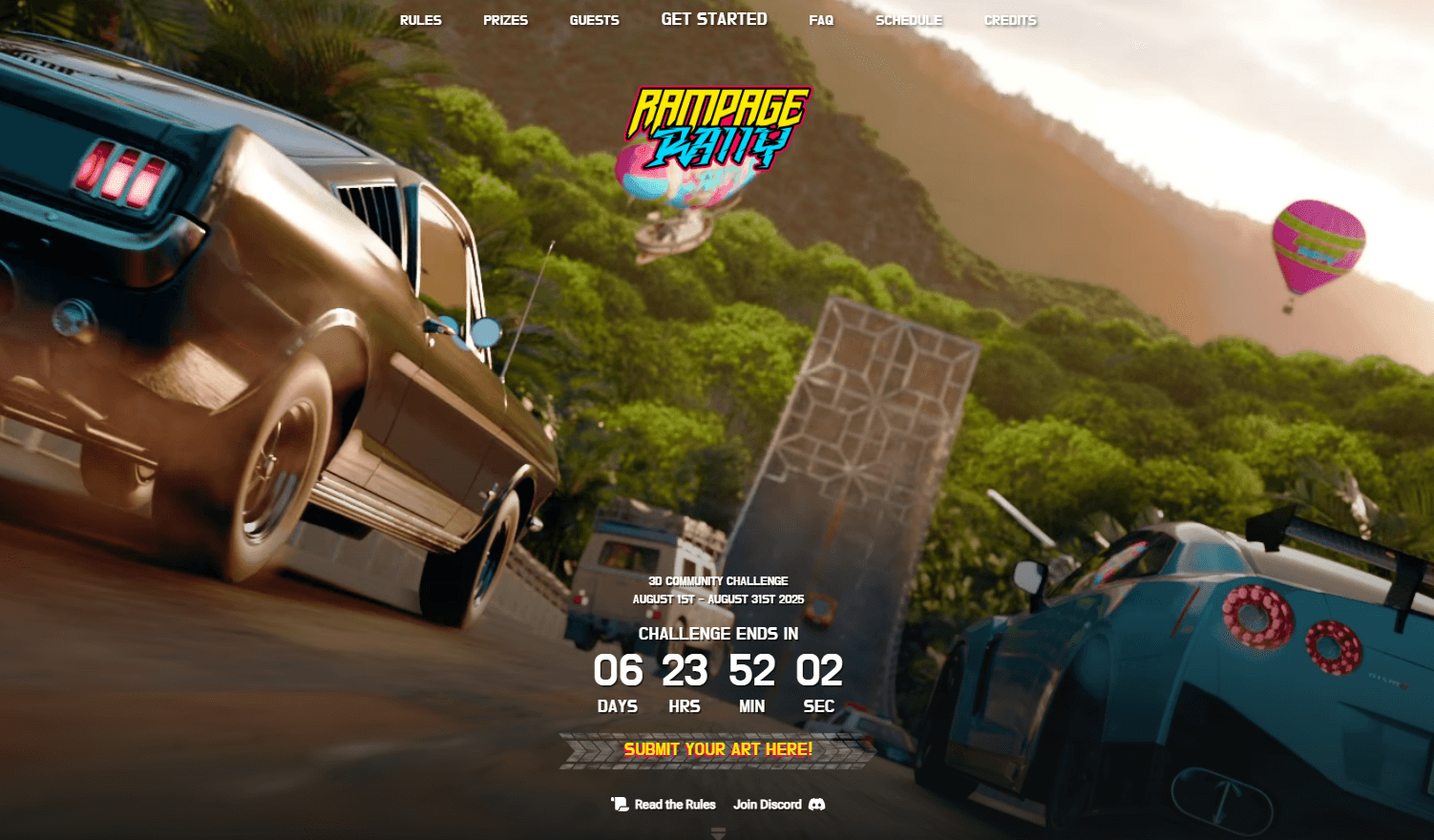
2025 第11届世界渲染大赛 “极限狂飙” 参赛指南:从创作到提交的完整流程
2025-08-25

世界渲染大赛奖金大公开!第十一届参赛者能拿多少?
2025-08-22
2026-06-26
vray云渲染怎么设置?vray云渲染提交任务前要注意什么?
2026-06-26
2026-06-26
2026-06-25
2026-06-25
2026-06-25
2026-06-25
2026-06-25









