动画渲染
兼容90%CG软件,渲染提速400倍





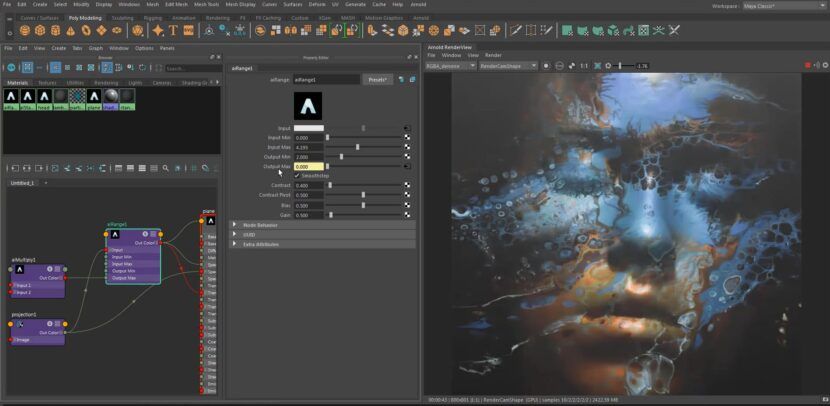



从新手到专家:2025瑞云渲染Clarisse插件对比与进阶使用指南
2025-04-02

第10届世界渲染大赛TOP100!中国选手的动画渲染作品赏析!!看看有没有你喜欢的风格
2025-03-27

全球顶尖动画渲染作品集结:第十届世界渲染大赛前五名精彩回顾
2025-03-27

网络渲染哪个好?网络在线渲染平台哪个好
2025-01-09

c4d怎么让背景衔接地面无缝
2025-01-07

如何利用云渲染服务,提升影视项目的渲染效率?
2024-12-30
2025-07-01
2025-07-01
2025-06-28
2025-06-26
2025-06-26
2025-06-23
2025-06-23
2025年最新建模渲染效果图软件大对比:哪款最适合你的需求?
2025-06-20








